
Integrazione IA
Soluzioni RAG
Sblocca il pieno potenziale dei tuoi dati aziendali con Retrieval Augmented Generation – il ponte intelligente tra la tua conoscenza e l'intelligenza artificiale.
Sblocca il pieno potenziale dei tuoi dati aziendali con Retrieval Augmented Generation – il ponte intelligente tra la tua conoscenza e l'intelligenza artificiale.
Hai sempre voluto utilizzare le tue basi di conoscenza interne per l'IA? Ti sei chiesto come i tuoi dipendenti possano accedere più velocemente alla conoscenza aziendale? O come costruire un assistente IA che comprenda veramente di cosa parla la tua azienda?
È esattamente qui che entra in gioco Retrieval Augmented Generation (RAG). Questa tecnologia consente di arricchire i Large Language Models (LLM) come ChatGPT con i tuoi dati – senza la costosa e dispendiosa formazione del tuo modello.
Le tue fonti di dati diventano utilizzabili: wiki Confluence, documenti SharePoint, manuali PDF, file Word, documentazione di processo, specifiche tecniche, sistemi di ticket di supporto clienti – tutte queste preziose informazioni possono essere integrate senza soluzione di continuità in soluzioni alimentate dall'IA.
Casi d'uso concreti:
Nessuna costosa formazione LLM necessaria – usa i modelli esistenti con i tuoi dati
I dati sensibili rimangono nella tua infrastruttura, nessuna condivisione con modelli di formazione esterni
Ogni dichiarazione è collegata alla fonte originale – trasparente e tracciabile
I nuovi documenti diventano immediatamente disponibili senza riaddestramento del modello
Le risposte sono basate sui tuoi documenti reali, non sulla conoscenza generale del modello
Da pochi documenti a estese basi di conoscenza – RAG cresce con te
RAG funziona in due fasi fondamentali: La fase di configurazione, dove la tua base di conoscenza viene preparata una volta, e la fase di recupero, che viene eseguita in tempo reale ad ogni richiesta.
Questa fase deve essere eseguita solo una volta – o ogni volta che desideri aggiornare la tua base di conoscenza. A seconda delle dimensioni della tua base documentale, questo processo può richiedere da pochi minuti a diverse ore. Il vantaggio: una volta creati, gli embeddings sono disponibili per query ultraveloci.
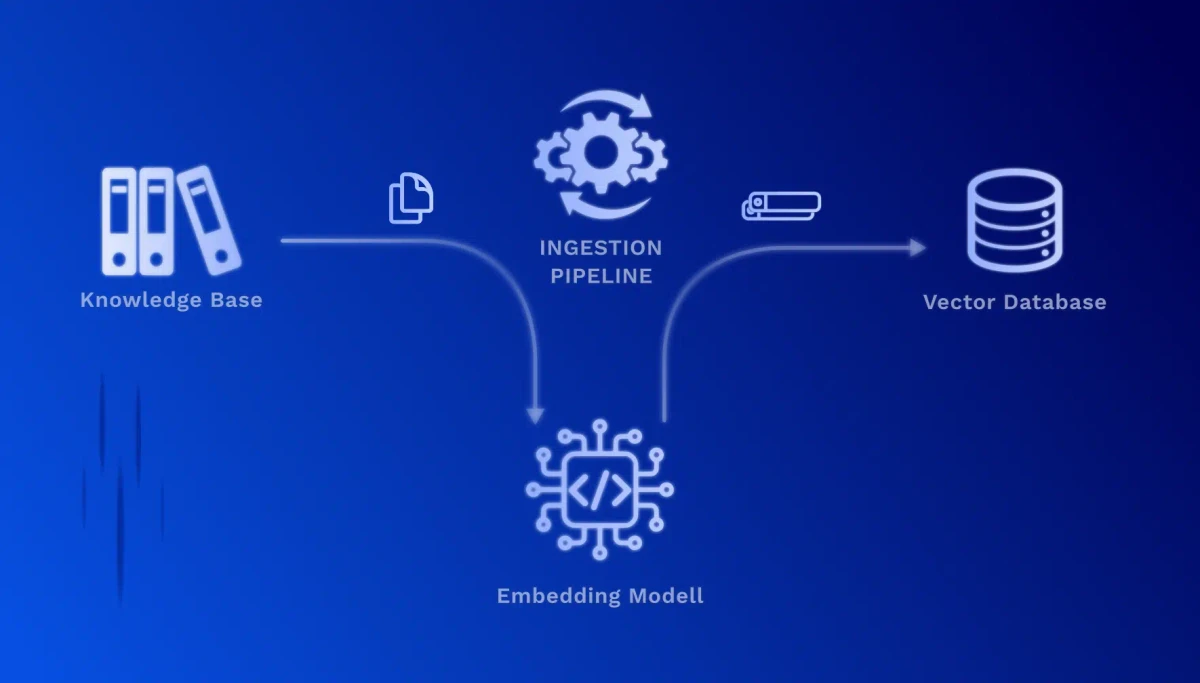
1. Preparazione dei documenti (chunking): I tuoi documenti vengono divisi in sezioni di testo significative e gestibili. Un manuale tecnico, ad esempio, viene suddiviso in singoli capitoli, sezioni o passaggi di processo.
2. Vettorizzazione (embedding): Ogni sezione di testo viene convertita da un modello IA specializzato in un vettore numerico ad alta dimensione. Questi vettori catturano il significato semantico del testo – contenuti simili ricevono vettori simili, anche se vengono usate parole diverse.
3. Archiviazione in un database vettoriale: I vettori vengono memorizzati insieme ai testi originali e ai metadati (fonte, data, autore) in un database specializzato. Questo consente ricerche di similarità estremamente veloci su milioni di documenti.
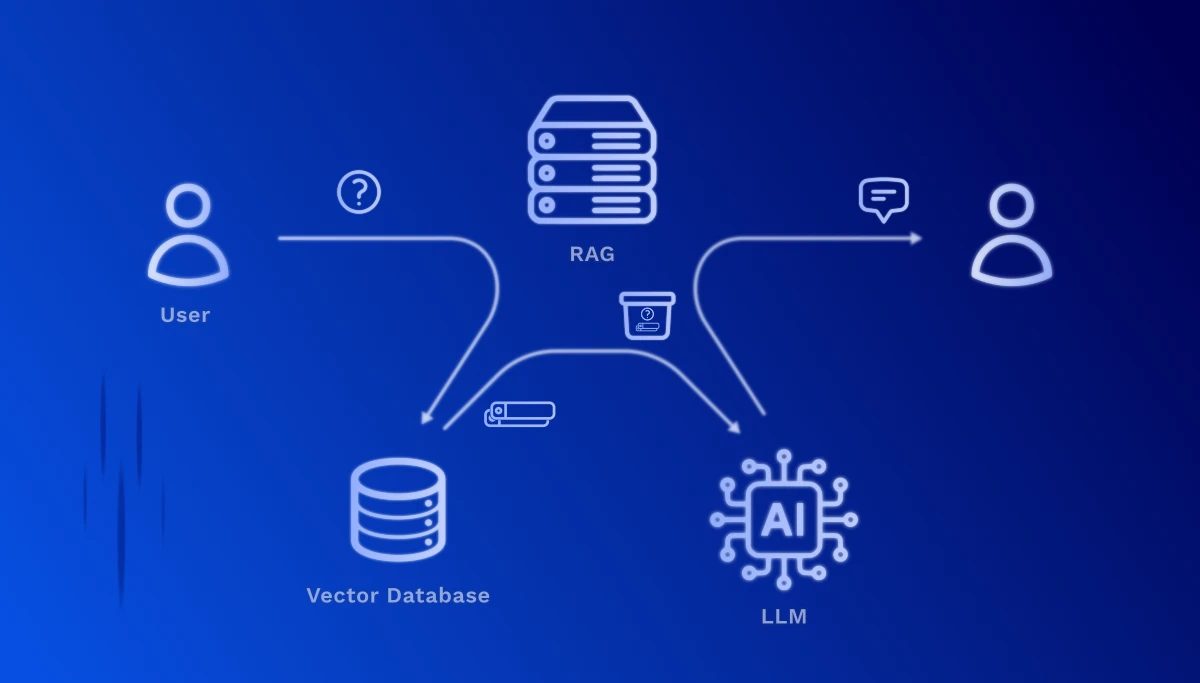
1. Elaborazione della richiesta: Quando un utente fa una domanda, viene anch'essa convertita in un vettore – utilizzando lo stesso modello di embedding della preparazione dei documenti.
2. Ricerca semantica: Il sistema calcola ora la similarità tra il vettore della domanda e tutti i vettori dei documenti memorizzati. Le sezioni di testo più rilevanti vengono identificate – basate sul significato, non solo sulle corrispondenze di parole chiave.
3. Arricchimento del contesto: I passaggi di testo rilevanti trovati vengono passati come contesto al Large Language Model (ad esempio, GPT-4, Claude). Il modello riceve quindi sia la domanda originale che le informazioni corrispondenti dai tuoi documenti.
4. Generazione intelligente della risposta: L'LLM formula ora una risposta precisa basata sui tuoi dati aziendali reali – completa di riferimenti alle fonti, in modo che l'utente possa consultare i passaggi originali.
RAG è una tecnologia potente, ma porta anche sfide pratiche che padroneggiamo insieme a te:
Ottimizzare la dimensione dei chunk: Sezioni di testo troppo piccole perdono contesto, troppo grandi riducono la precisione. Troviamo l'equilibrio ottimale per i tuoi tipi di documenti – da FAQ brevi a manuali tecnici completi.
Contenuto multimodale: Molti documenti contengono non solo testo, ma anche diagrammi, tabelle e immagini. I moderni sistemi RAG possono ora elaborare anche contenuti visivi e includerli nella ricerca – una sfida che risolviamo con modelli specializzati.
Utilizzare i metadati: Data, autore, reparto, tipo di documento – queste informazioni aiutano a filtrare e dare priorità ai risultati di ricerca. Strutturiamo i tuoi metadati per offrire il massimo valore.
Con la nostra esperienza nelle implementazioni RAG, ti accompagniamo dalla prima concezione all'uso produttivo – su misura per le tue esigenze specifiche e strutture di dati.
Esploriamo insieme come RAG può migliorare i tuoi processi interni e fornire risposte migliori ai tuoi dipendenti e clienti.
Contattaci