
Intégration IA
Solutions RAG
Libérez tout le potentiel de vos données d'entreprise avec Retrieval Augmented Generation – le pont intelligent entre vos connaissances et l'intelligence artificielle.
Libérez tout le potentiel de vos données d'entreprise avec Retrieval Augmented Generation – le pont intelligent entre vos connaissances et l'intelligence artificielle.
Avez-vous toujours voulu utiliser vos bases de connaissances internes pour l'IA ? Vous êtes-vous demandé comment vos employés peuvent accéder plus rapidement aux connaissances de l'entreprise ? Ou comment construire un assistant IA qui comprend vraiment de quoi parle votre entreprise ?
C'est exactement là qu'intervient Retrieval Augmented Generation (RAG). Cette technologie permet d'enrichir les Large Language Models (LLM) comme ChatGPT avec vos propres données – sans la formation coûteuse et chronophage de votre propre modèle.
Vos sources de données deviennent utilisables : wikis Confluence, documents SharePoint, manuels PDF, fichiers Word, documentation de processus, spécifications techniques, systèmes de tickets de support client – toutes ces informations précieuses peuvent être intégrées de manière transparente dans des solutions alimentées par l'IA.
Cas d'usage concrets :
Pas besoin de formation LLM coûteuse – utilisez les modèles existants avec vos données
Les données sensibles restent dans votre infrastructure, aucun partage avec des modèles de formation externes
Chaque déclaration est liée à la source originale – transparent et traçable
Les nouveaux documents deviennent immédiatement disponibles sans réentraînement du modèle
Les réponses sont basées sur vos documents réels, pas sur les connaissances générales du modèle
De quelques documents à des bases de connaissances étendues – RAG grandit avec vous
RAG fonctionne en deux phases fondamentales : La phase de configuration, où votre base de connaissances est préparée une fois, et la phase de récupération, qui s'exécute en temps réel à chaque requête.
Cette phase ne doit être effectuée qu'une seule fois – ou chaque fois que vous souhaitez mettre à jour votre base de connaissances. Selon la taille de votre base documentaire, ce processus peut prendre de quelques minutes à plusieurs heures. L'avantage : une fois créés, les embeddings sont disponibles pour des requêtes ultra-rapides.
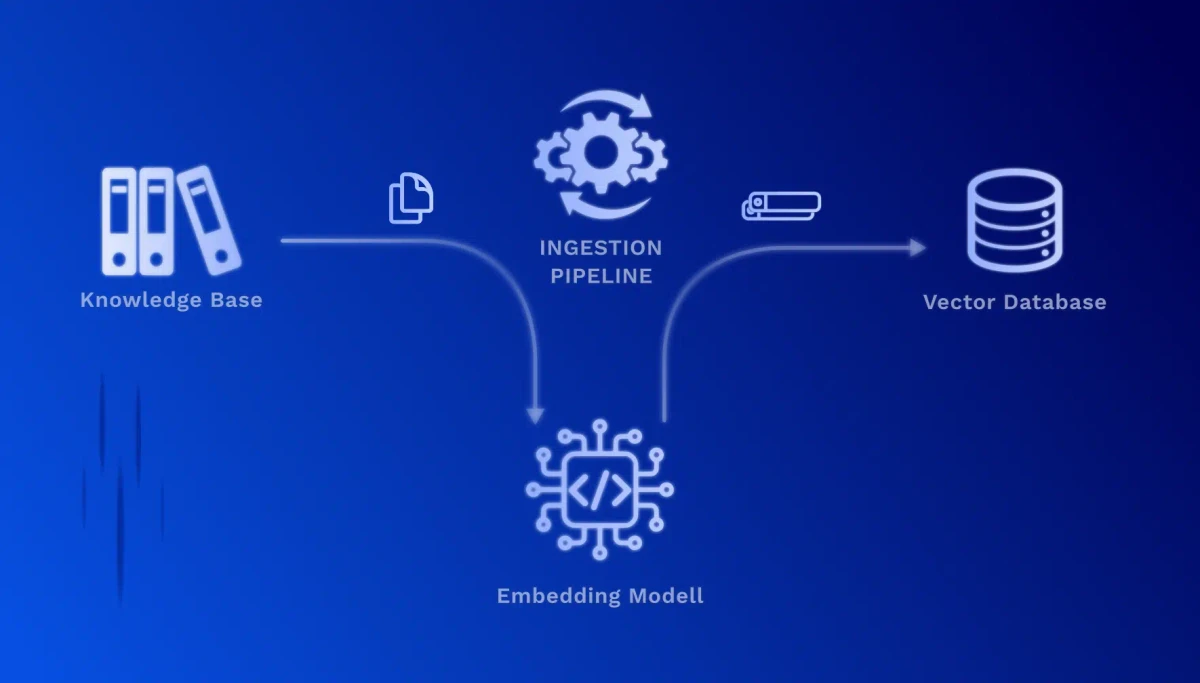
1. Préparation des documents (chunking) : Vos documents sont divisés en sections de texte significatives et gérables. Un manuel technique, par exemple, est décomposé en chapitres, sections ou étapes de processus individuels.
2. Vectorisation (embedding) : Chaque section de texte est convertie par un modèle IA spécialisé en un vecteur numérique de haute dimension. Ces vecteurs capturent le sens sémantique du texte – un contenu similaire reçoit des vecteurs similaires, même si des mots différents sont utilisés.
3. Stockage dans une base de données vectorielle : Les vecteurs sont stockés avec les textes originaux et les métadonnées (source, date, auteur) dans une base de données spécialisée. Cela permet des recherches de similarité extrêmement rapides sur des millions de documents.
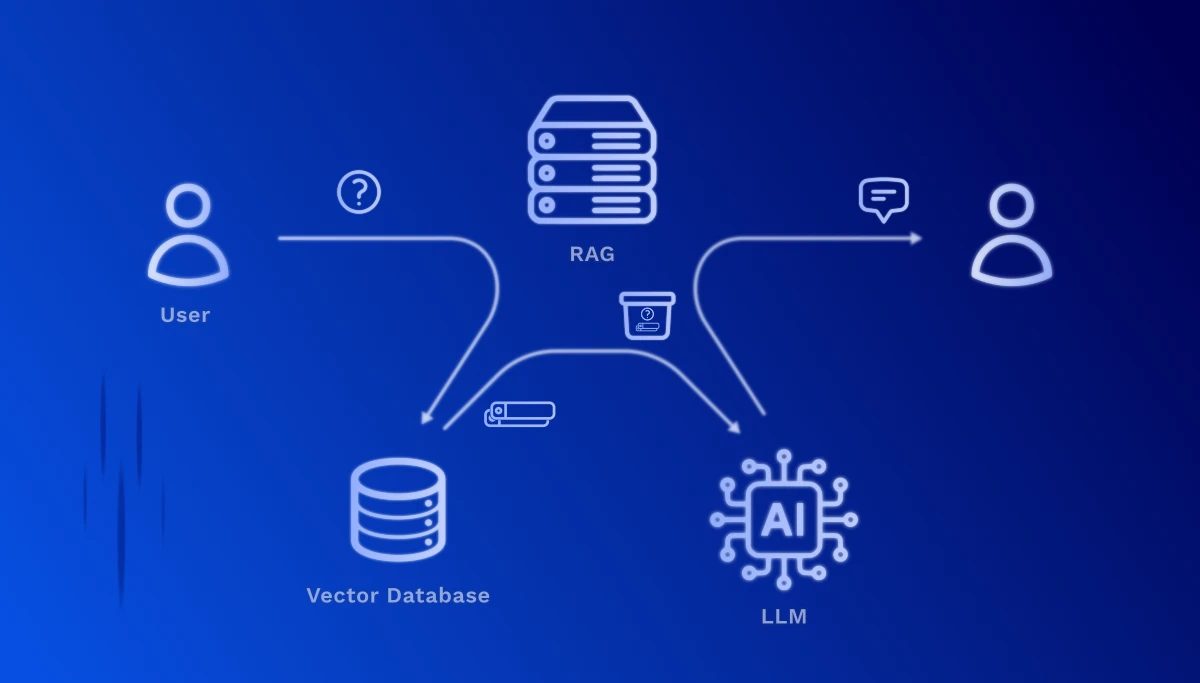
1. Traitement de la requête : Lorsqu'un utilisateur pose une question, elle est également convertie en vecteur – en utilisant le même modèle d'embedding que lors de la préparation des documents.
2. Recherche sémantique : Le système calcule maintenant la similarité entre le vecteur de question et tous les vecteurs de documents stockés. Les sections de texte les plus pertinentes sont identifiées – basées sur le sens, pas seulement sur les correspondances de mots-clés.
3. Enrichissement du contexte : Les passages de texte pertinents trouvés sont transmis comme contexte au Large Language Model (par exemple, GPT-4, Claude). Le modèle reçoit ainsi à la fois la question originale et les informations correspondantes de vos documents.
4. Génération de réponse intelligente : Le LLM formule maintenant une réponse précise basée sur vos données d'entreprise réelles – complète avec des références sources, afin que l'utilisateur puisse consulter les passages originaux.
RAG est une technologie puissante, mais apporte également des défis pratiques que nous maîtrisons ensemble avec vous :
Optimiser la taille des chunks : Les sections de texte trop petites perdent le contexte, trop grandes réduisent la précision. Nous trouvons l'équilibre optimal pour vos types de documents – des FAQ courtes aux manuels techniques complets.
Contenu multimodal : Beaucoup de documents contiennent non seulement du texte, mais aussi des diagrammes, tableaux et images. Les systèmes RAG modernes peuvent maintenant également traiter le contenu visuel et l'inclure dans la recherche – un défi que nous résolvons avec des modèles spécialisés.
Utiliser les métadonnées : Date, auteur, département, type de document – ces informations aident à filtrer et prioriser les résultats de recherche. Nous structurons vos métadonnées pour offrir une valeur maximale.
Avec notre expérience dans les implémentations RAG, nous vous accompagnons de la première conception à l'utilisation productive – adaptée à vos exigences spécifiques et structures de données.
Explorons ensemble comment RAG peut améliorer vos processus internes et fournir de meilleures réponses à vos employés et clients.
Nous contacter