
AI Integration
RAG Solutions
Unlock the full potential of your company data with Retrieval Augmented Generation – the intelligent bridge between your knowledge and artificial intelligence.
Unlock the full potential of your company data with Retrieval Augmented Generation – the intelligent bridge between your knowledge and artificial intelligence.
Have you always wanted to use your internal knowledge bases for AI? Have you wondered how your employees can access company knowledge faster? Or how to build an AI assistant that truly understands what your company is about?
This is exactly where Retrieval Augmented Generation (RAG) comes in. This technology enables Large Language Models (LLMs) like ChatGPT to be enriched with your own data – without the costly and time-consuming training of your own model.
Your data sources become usable: Confluence wikis, SharePoint documents, PDF manuals, Word files, process documentation, technical specifications, customer support ticket systems – all this valuable information can be seamlessly integrated into AI-powered solutions.
Concrete use cases:
No expensive LLM training needed – use existing models with your data
Sensitive data remains in your infrastructure, no sharing with external training models
Every statement is linked to the original source – transparent and traceable
New documents become immediately available without retraining the model
Answers are based on your actual documents, not on general model knowledge
From a few documents to extensive knowledge bases – RAG grows with you
RAG works in two fundamental phases: The setup phase, where your knowledge base is prepared once, and the retrieval phase, which runs in real-time with each query.
This phase only needs to be performed once – or whenever you want to update your knowledge base. Depending on the size of your document base, this process can take from a few minutes to several hours. The advantage: Once created, the embeddings are available for lightning-fast queries.
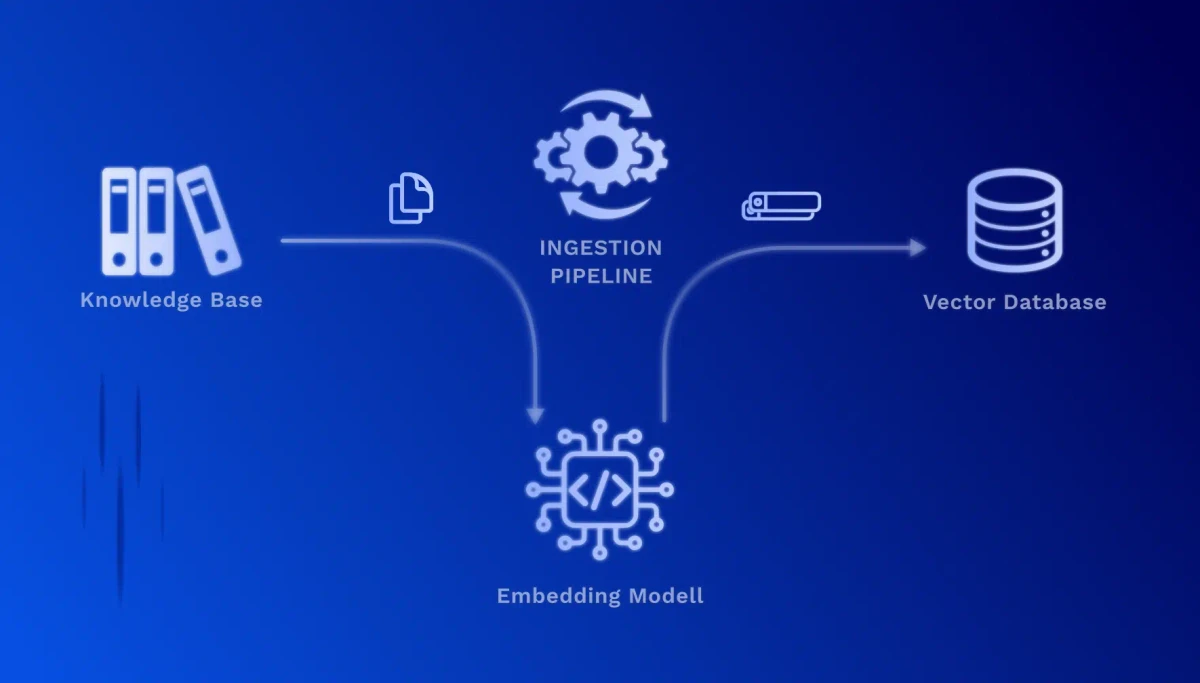
1. Document preparation (chunking): Your documents are divided into meaningful, manageable text sections. A technical manual, for example, is broken down into individual chapters, sections, or process steps.
2. Vectorization (embedding): Each text section is converted by a specialized AI model into a high-dimensional numerical vector. These vectors capture the semantic meaning of the text – similar content receives similar vectors, even if different words are used.
3. Storage in a vector database: The vectors are stored together with the original texts and metadata (source, date, author) in a specialized database. This enables extremely fast similarity searches across millions of documents.
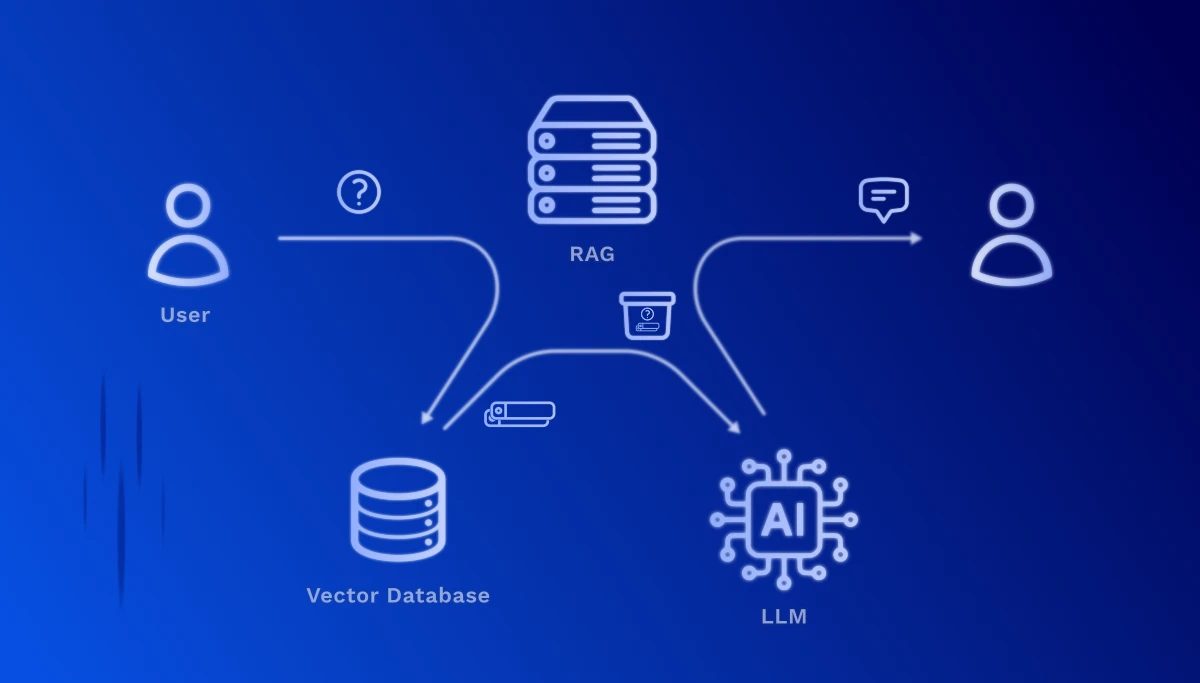
1. Query processing: When a user asks a question, it is also converted into a vector – using the same embedding model as in document preparation.
2. Semantic search: The system now calculates the similarity between the question vector and all stored document vectors. The most relevant text sections are identified – based on meaning, not just keyword matches.
3. Context enrichment: The found relevant text passages are passed as context to the Large Language Model (e.g., GPT-4, Claude). The model thus receives both the original question and the matching information from your documents.
4. Intelligent answer generation: The LLM now formulates a precise answer based on your actual company data – complete with source references, so the user can look up the original passages.
RAG is a powerful technology, but also brings practical challenges that we master together with you:
Optimize chunk size: Text sections that are too small lose context, too large reduce precision. We find the optimal balance for your document types – from short FAQs to comprehensive technical manuals.
Multimodal content: Many documents contain not only text, but also diagrams, tables, and images. Modern RAG systems can now also process visual content and include it in the search – a challenge we solve with specialized models.
Use metadata: Date, author, department, document type – this information helps filter and prioritize search results. We structure your metadata to provide maximum value.
With our experience in RAG implementations, we accompany you from the first conception to productive use – tailored to your specific requirements and data structures.
Let's explore together how RAG can improve your internal processes and deliver better answers to your employees and customers.
Get in touch