
KI-Integration
RAG-Lösungen
Nutzen Sie das volle Potenzial Ihrer Unternehmensdaten mit Retrieval Augmented Generation – die intelligente Brücke zwischen Ihrem Wissen und künstlicher Intelligenz.
Nutzen Sie das volle Potenzial Ihrer Unternehmensdaten mit Retrieval Augmented Generation – die intelligente Brücke zwischen Ihrem Wissen und künstlicher Intelligenz.
Wollten Sie schon immer Ihre internen Wissensdatenbanken für KI nutzen? Haben Sie sich gefragt, wie Ihre Mitarbeiter schneller auf Unternehmenswissen zugreifen können? Oder wie Sie einen KI-Assistenten aufbauen, der wirklich versteht, wovon Ihr Unternehmen spricht?
Genau hier setzt Retrieval Augmented Generation (RAG) an. Diese Technologie ermöglicht es, Large Language Models (LLMs) wie ChatGPT mit Ihren eigenen Daten anzureichern – ohne das kostenspielige und zeitaufwändige Training eines eigenen Modells.
Ihre Datenquellen werden nutzbar: Confluence-Wikis, SharePoint-Dokumente, PDF-Handbücher, Word-Dateien, Prozessdokumentationen, technische Spezifikationen, Ticketsysteme für den Kundensupport – all diese wertvollen Informationen können nahtlos in KI-gestützte Lösungen integriert werden.
Konkrete Anwendungsbeispiele:
Keine teuren LLM-Trainings nötig – nutzen Sie bestehende Modelle mit Ihren Daten
Sensible Daten bleiben in Ihrer Infrastruktur, keine Weitergabe an externe Trainingsmodelle
Jede Aussage ist mit der Originalquelle verlinkt – transparent und nachvollziehbar
Neue Dokumente werden sofort verfügbar, ohne Neutraining des Modells
Antworten basieren auf Ihren echten Dokumenten, nicht auf allgemeinem Modellwissen
Von wenigen Dokumenten bis zu umfangreichen Wissensdatenbanken – RAG wächst mit
RAG funktioniert in zwei grundlegenden Phasen: Die Einrichtungsphase, in der Ihre Wissensbasis einmalig vorbereitet wird, und die Retrieval-Phase, die bei jeder Anfrage in Echtzeit abläuft.
Diese Phase muss nur einmal durchgeführt werden – oder wenn Sie Ihre Wissensbasis aktualisieren möchten. Je nach Größe Ihrer Dokumentenbasis kann dieser Prozess von wenigen Minuten bis zu mehreren Stunden dauern. Der Vorteil: Einmal erstellt, stehen die Embeddings für blitzschnelle Abfragen zur Verfügung.
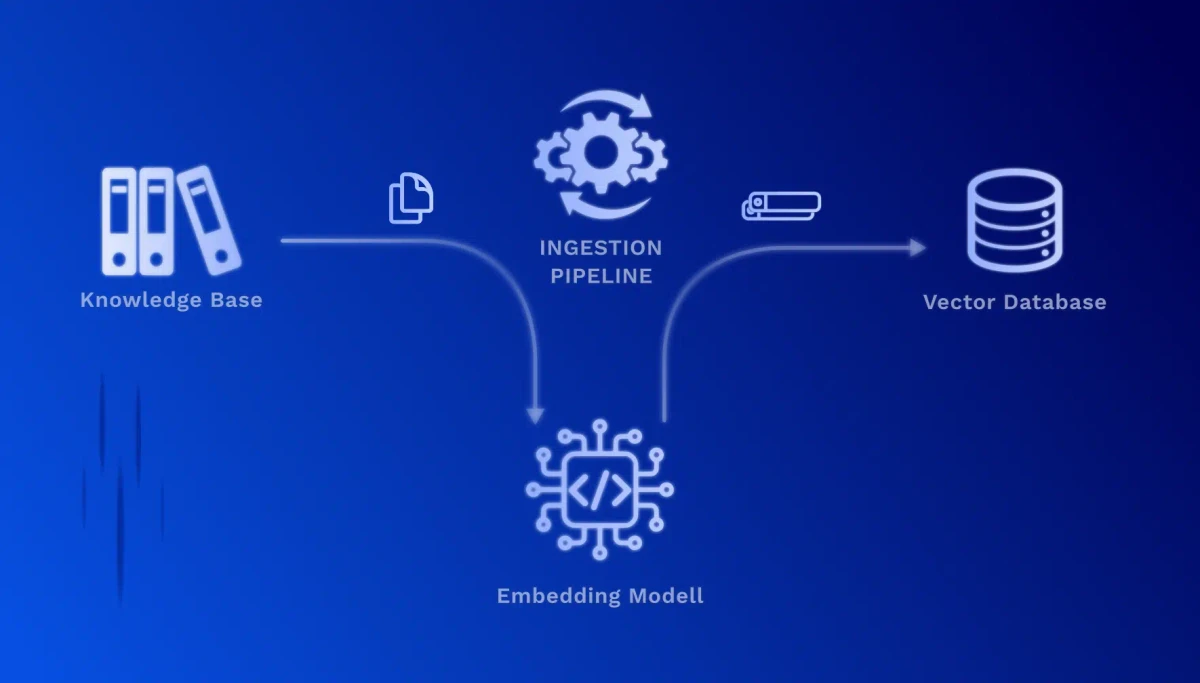
1. Dokumentenvorbereitung (Chunking): Ihre Dokumente werden in sinnvolle, überschaubare Textabschnitte aufgeteilt. Ein technisches Handbuch wird beispielsweise in einzelne Kapitel, Abschnitte oder Prozessschritte zerlegt.
2. Vektorisierung (Embedding): Jeder Textabschnitt wird durch ein spezialisiertes KI-Modell in einen hochdimensionalen Zahlenvektor umgewandelt. Diese Vektoren erfassen die semantische Bedeutung des Textes – ähnliche Inhalte erhalten ähnliche Vektoren, auch wenn unterschiedliche Worte verwendet werden.
3. Speicherung in einer Vektordatenbank: Die Vektoren werden zusammen mit den Originaltexten und Metadaten (Quelle, Datum, Autor) in einer spezialisierten Datenbank gespeichert. Dies ermöglicht extrem schnelle Ähnlichkeitssuchen über Millionen von Dokumenten.
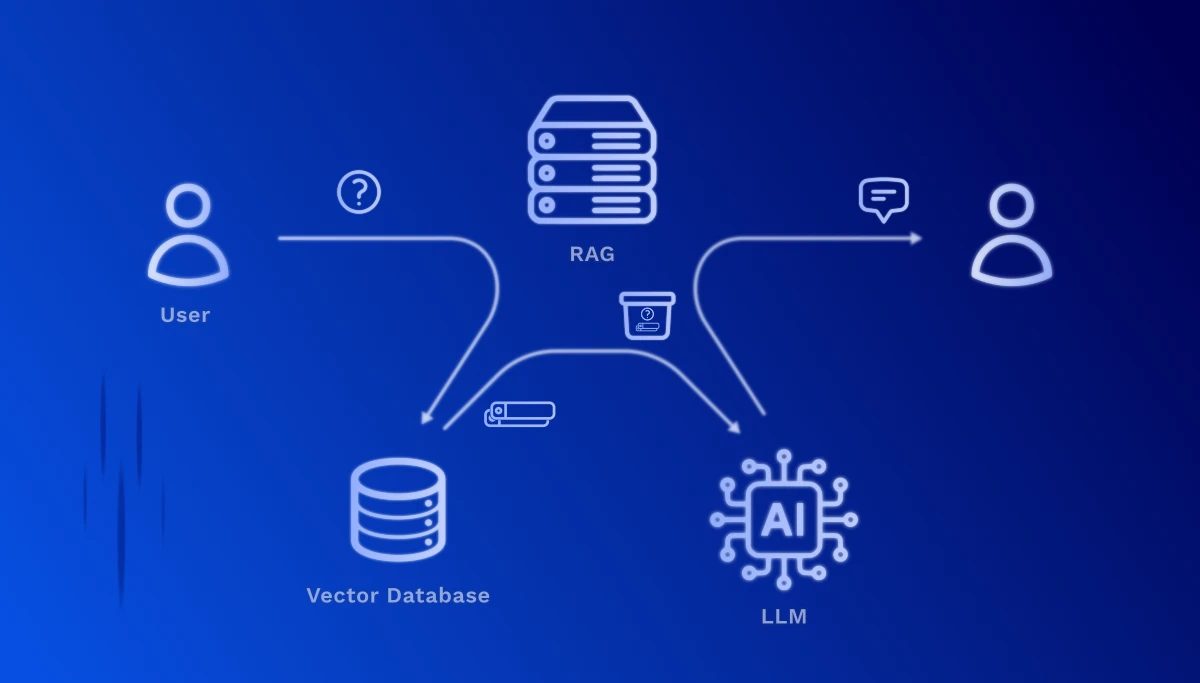
1. Anfrage-Verarbeitung: Wenn ein Nutzer eine Frage stellt, wird diese ebenfalls in einen Vektor umgewandelt – mit dem gleichen Embedding-Modell wie bei der Dokumentenvorbereitung.
2. Semantische Suche: Das System berechnet nun die Ähnlichkeit zwischen dem Frage-Vektor und allen gespeicherten Dokumenten-Vektoren. Die relevantesten Textabschnitte werden identifiziert – und zwar basierend auf Bedeutung, nicht nur auf Schlagwortübereinstimmungen.
3. Kontextanreicherung: Die gefundenen, relevanten Textpassagen werden als Kontext an das Large Language Model (z.B. GPT-4, Claude) übergeben. Das Modell erhält also sowohl die ursprüngliche Frage als auch die passenden Informationen aus Ihren Dokumenten.
4. Intelligente Antwortgenerierung: Das LLM formuliert nun eine präzise Antwort, die auf Ihren echten Unternehmensdaten basiert – komplett mit Quellenangaben, sodass der Nutzer die Originalstellen nachschlagen kann.
RAG ist eine leistungsstarke Technologie, bringt aber auch praktische Herausforderungen mit sich, die wir gemeinsam mit Ihnen meistern:
Chunk-Größe optimieren: Zu kleine Textabschnitte verlieren Kontext, zu große reduzieren die Präzision. Wir finden die optimale Balance für Ihre Dokumententypen – von kurzen FAQs bis zu umfangreichen technischen Handbüchern.
Multimodale Inhalte: Viele Dokumente enthalten nicht nur Text, sondern auch Diagramme, Tabellen und Bilder. Moderne RAG-Systeme können mittlerweile auch visuelle Inhalte verarbeiten und in die Suche einbeziehen – eine Herausforderung, die wir mit spezialisierten Modellen lösen.
Metadaten nutzen: Datum, Autor, Abteilung, Dokumententyp – diese Informationen helfen, Suchergebnisse zu filtern und zu priorisieren. Wir strukturieren Ihre Metadaten so, dass sie maximalen Mehrwert bringen.
Mit unserer Erfahrung in RAG-Implementierungen begleiten wir Sie von der ersten Konzeption bis zum produktiven Einsatz – zugeschnitten auf Ihre spezifischen Anforderungen und Datenstrukturen.
Lassen Sie uns gemeinsam erkunden, wie RAG Ihre internen Prozesse verbessern und Ihren Mitarbeitern sowie Kunden bessere Antworten liefern kann.
Kontakt